Slicing and Dicing¶
Note
Examples are in Python and in Slicer HTTP requests.
Browser¶
The aggregation, slicing, dicing, browsing of the multi-dimensional data is being done by an AggregationBrowser.
from cubes import Workspace
workspace = Workspace("slicer.ini")
browser = workspace.browser()
Cell and Cuts¶
Cell defines a point of interest – portion of the cube to be aggergated or browsed.
There are three types of cells: point – defines a single point in a dimension at a prticular level; range – defines all points of an ordered dimension (such as date) within the range and set – collection of points:
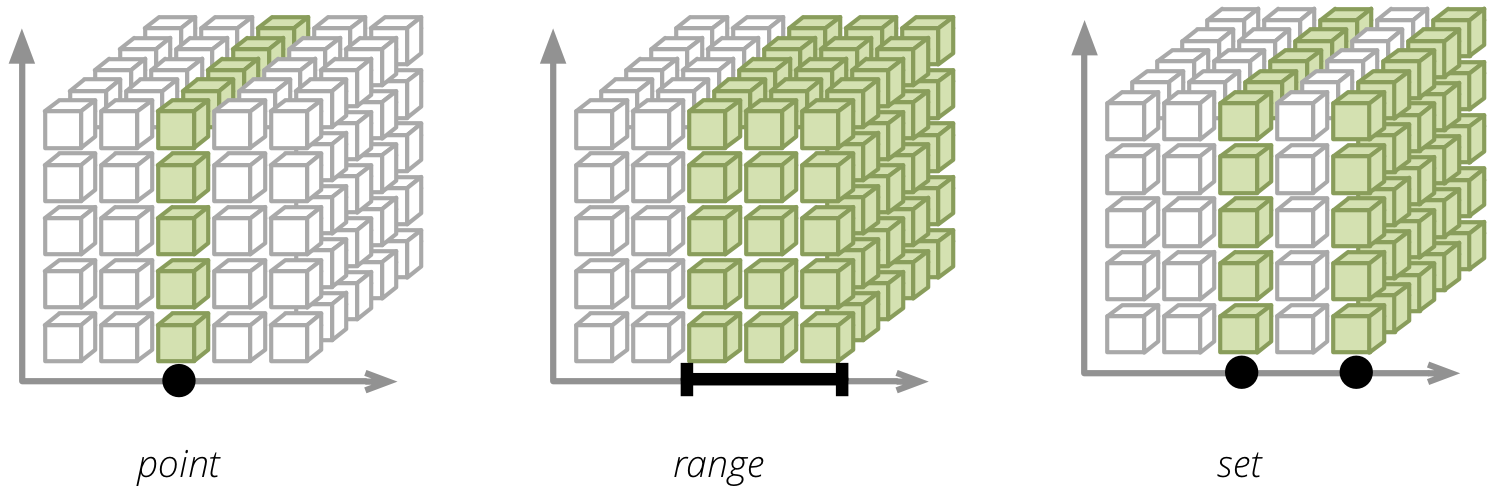
Points are defined as dimension paths – list of dimension level keys. For example a date path for 24th of December 2010 would be: [2010, 12, 24]. For December 2010, regardless of day: [2010, 12] and for the whole year: it would be a single item list [2010]. Similar for other dimensions: ["sk", "Bratislava"] for city Bratislava in Slovakia (code sk).
In Python the cuts for “sales in Slovakia between June 2010 and June 2013” are defined as:
cuts = [
PointCut("geography", ["sk"]),
PointCut("date", [2010, 6], [2012, 6])
]
Same cuts for Slicer: cut=geography:sk|date:2010,6-2012,6.
If a different hierarchy than default is desired – “from the second quartal of 2010 to the second quartal of 2012”:
cuts = [
PointCut("date", [2010, 2], [2012, 2], hierarchy="yqmd")
]
Slicer: cut=date@yqmd:2010,2-2012,2.
Ranges and sets might have unequal depths: from [2010] to [2012,12,24] means “from the beginning of the year 2010 to December 24th 2012”.
cuts = [
PointCut("date", [2010], [2012, 12, 24])
]
Slicer: cut=date:2010-2012,12,24.
Ranges might be open, such as “everything until Dec 24 2012”:
cuts = [
PointCut("date", None, [2012, 12, 24])
]
Slicer: cut=date:-2012,12,24.
Aggregate¶
browser = workspace.browser("sales")
result = browser.aggregate()
print result.summary
Slicer: /cube/sales/aggregate
Aggregate of a cell:
cuts = [
PointCut("geography", ["sk"])
PointCut("date", [2010, 6], [2012, 6]),
]
cell = Cell(cube, cuts)
result = browser.aggregate(cell)
Slicer: /cube/sales/aggregate?cut=geography:sk|date:2010,6-2012,6
Drilldown¶
Drill-down – get more details, group the aggregation by dimension members.
For example “sales by month in 2010”:
cut = PointCut("date", [2010])
cell = Cell(cube, [cut])
result = browser.aggregate(cell, drilldown=["date"])
for row in result:
print "%s: %s" % (row["date.year"], row["amount_sum"])
Slicer: /cube/sales/aggregate?cut=date:2010&drilldown=date
Todo
- implicit/explicit drilldown
- aggregate(cell, drilldown)
- aggregate(cell, aggregates, drilldown)
- aggregate(cell, drilldown, page, page_size)
- dim
- dim:level
- dim@hierarchy:level
Facts¶
- facts()
- facts(cell)
- facts(cell, fields)
Fact¶
- fact(id)
Members¶
- members(cell, dimension)
- members(cell, dimension, depth)
- members(cell, dimension, depth, hierarchy)
Cell Details¶
When we are browsing a cube, the cell provides current browsing context. For aggregations and selections to happen, only keys and some other internal attributes are necessary. Those can not be presented to the user though. For example we have geography path (country, region) as ['sk', 'ba'], however we want to display to the user Slovakia for the country and Bratislava for the region. We need to fetch those values from the data store. Cell details is basically a human readable description of the current cell.
For applications where it is possible to store state between aggregation calls, we can use values from previous aggregations or value listings. Problem is with web applications - sometimes it is not desirable or possible to store whole browsing context with all details. This is exact the situation where fetching cell details explicitly might come handy.
The cell details are provided by method cubes.AggregationBrowser.cell_details() which has Slicer HTTP equivalent /cell or {"query":"detail", ...} in /report request (see the server documentation for more information).
For point cuts, the detail is a list of dictionaries for each level. For example our previously mentioned path ['sk', 'ba'] would have details described as:
[
{
"geography.country_code": "sk",
"geography.country_name": "Slovakia",
"geography.something_more": "..."
"_key": "sk",
"_label": "Slovakia"
},
{
"geography.region_code": "ba",
"geography.region_name": "Bratislava",
"geography.something_even_more": "...",
"_key": "ba",
"_label": "Bratislava"
}
]
You might have noticed the two redundant keys: _key and _label - those contain values of a level key attribute and level label attribute respectively. It is there to simplify the use of the details in presentation layer, such as templates. Take for example doing only one-dimensional browsing and compare presentation of “breadcrumbs”:
labels = [detail["_label"] for detail in cut_details]
Which is equivalent to:
levels = dimension.hierarchy().levels()
labels = []
for i, detail in enumerate(cut_details):
labels.append(detail[level[i].label_attribute.ref()])
Note that this might change a bit: either full detail will be returned or just key and label, depending on an option argument (not yet decided).