Aggregation Browser Reference¶
Abstraction for aggregated browsing (concrete implementation is provided by one of the backends in package backend or a custom backend).
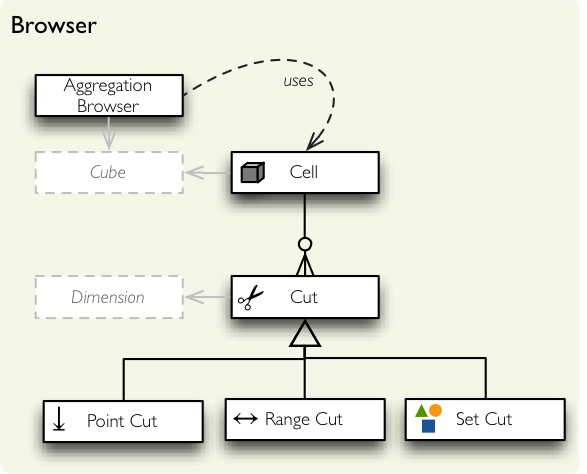
Browser package classes.
Aggregate browsing¶
- class cubes.AggregationBrowser(cube, store=None, locale=None, metadata=None, **options)¶
Creates and initializes the aggregation browser. Subclasses should override this method.
- aggregate(cell=None, aggregates=None, drilldown=None, split=None, measures=None, **options)¶
Return aggregate of a cell.
Subclasses of aggregation browser should implement this method.
Attributes:
- drilldown - dimensions and levels through which to drill-down, default None
- aggregates - list of aggregate measures. By default all cube’s aggregates are included in the result.
Drill down can be specified in two ways: as a list of dimensions or as a dictionary. If it is specified as list of dimensions, then cell is going to be drilled down on the next level of specified dimension. Say you have a cell for year 2010 and you want to drill down by months, then you specify drilldown = ["date"].
If drilldown is a dictionary, then key is dimension or dimension name and value is last level to be drilled-down by. If the cell is at year level and drill down is: { "date": "day" } then both month and day levels are added.
If there are no more levels to be drilled down, an exception is raised. Say your model has three levels of the date dimension: year, month, day and you try to drill down by date at the next level then ValueError will be raised.
Retruns a :class:AggregationResult object.
- assert_low_cardinality(cell, drilldown)¶
Raises ArgumentError when there is drilldown through high cardinality dimension or level and there is no condition in the cell for the level.
- cell_details(cell=None, dimension=None)¶
Returns details for the cell. Returned object is a list with one element for each cell cut. If dimension is specified, then details only for cuts that use the dimension are returned.
Default implemenatation calls AggregationBrowser.cut_details() for each cut. Backends might customize this method to make it more efficient.
- cut_details(cut)¶
Gets details for a cut which should be a Cut instance.
- PointCut - all attributes for each level in the path
- SetCut - list of PointCut results, one per path in the set
- RangeCut - PointCut-like results for lower range (from) and upper range (to)
- fact(key)¶
Returns a single fact from cube specified by fact key key
- facts(cell=None, fields=None, **options)¶
Return an iterable object with of all facts within cell. fields is list of fields to be considered in the output.
Subclasses overriding this method sould return a Facts object and set it’s attributes to the list of selected attributes.
- features()¶
Returns a dictionary of available features for the browsed cube. Default implementation returns an empty dictionary.
Standard keys that might be present:
- actions – list of actions that can be done with the cube, such as facts, aggregate, members, ...
- post_processed_aggregates – list of aggregates that are computed after the result is fetched from the source (not natively).
Subclasses are advised to override this method.
- is_builtin_function(function_name, aggregate)¶
Returns True if function function_name for aggregate is bult-in. Returns False if the browser can not compute the function and post-aggregation calculation should be used.
Subclasses should override this method.
- members(cell, dimension, depth=None, hierarchy=None)¶
Return members of dimension with level depth depth. If depth is None, all levels are returned. If no hierarchy is specified, then default dimension hierarchy is used.
- prepare_aggregates(aggregates=None, measures=None)¶
Prepares the aggregate list for aggregatios. aggregates might be a list of aggregate names or MeasureAggregate objects.
Aggregates that are used in post-aggregation calculations are included in the result. This method is using is_builtin_function() to check whether the aggregate is native to the backend or not.
If measures are specified, then aggregates that refer tho the measures in the list are returned.
If no aggregates are specified then all cube’s aggregates are returned.
Note
Either specify aggregates or measures, not both.
- prepare_order(order, is_aggregate=False)¶
Prepares an order list.
- report(cell, queries)¶
Bundle multiple requests from queries into a single one.
Keys of queries are custom names of queries which caller can later use to retrieve respective query result. Values are dictionaries specifying arguments of the particular query. Each query should contain at least one required value query which contains name of the query function: aggregate, facts, fact, values and cell cell (for cell details). Rest of values are function specific, please refer to the respective function documentation for more information.
Example:
queries = { "product_summary" = { "query": "aggregate", "drilldown": "product" } "year_list" = { "query": "values", "dimension": "date", "depth": 1 } }Result is a dictionary where keys wil lbe the query names specified in report specification and values will be result values from each query call.:
result = browser.report(cell, queries) product_summary = result["product_summary"] year_list = result["year_list"]
This method provides convenient way to perform multiple common queries at once, for example you might want to have always on a page: total transaction count, total transaction amount, drill-down by year and drill-down by transaction type.
Raises cubes.ArgumentError when there are no queries specified or if a query is of unknown type.
Roll-up
Report queries might contain rollup specification which will result in “rolling-up” one or more dimensions to desired level. This functionality is provided for cases when you would like to report at higher level of aggregation than the cell you provided is in. It works in similar way as drill down in AggregationBrowser.aggregate() but in the opposite direction (it is like cd .. in a UNIX shell).
Example: You are reporting for year 2010, but you want to have a bar chart with all years. You specify rollup:
... "rollup": "date", ...
Roll-up can be:
- a string - single dimension to be rolled up one level
- an array - list of dimension names to be rolled-up one level
- a dictionary where keys are dimension names and values are levels to be rolled up-to
Future
In the future there might be optimisations added to this method, therefore it will become faster than subsequent separate requests. Also when used with Slicer OLAP service server number of HTTP call overhead is reduced.
Result¶
The result of aggregated browsing is returned as object:
- class cubes.AggregationResult(cell=None, aggregates=None)¶
Result of aggregation or drill down.
Attributes:
- cell – cell that this result is aggregate of
- summary - dictionary of summary row fields
- cells - list of cells that were drilled-down
- total_cell_count - number of total cells in drill-down (after limit, before pagination)
- aggregates – aggregate measures that were selected in aggregation
- remainder - summary of remaining cells (not yet implemented)
- levels – aggregation levels for dimensions that were used to drill- down
Note
Implementors of aggregation browsers should populate cell, measures and levels from the aggregate query.
- cached()¶
Return shallow copy of the receiver with cached cells. If cells are an iterator, they are all fetched in a list.
Warning
This might be expensive for large results.
- has_dimension(dimension)¶
Returns True if the result was drilled down by dimension (at any level)
- table_rows(dimension, depth=None, hierarchy=None)¶
Returns iterator of drilled-down rows which yields a named tuple with named attributes: (key, label, path, record). depth is last level of interest. If not specified (set to None) then deepest level for dimension is used.
- key: value of key dimension attribute at level of interest
- label: value of label dimension attribute at level of interest
- path: full path for the drilled-down cell
- is_base: True when dimension element is base (can not drill down more)
- record: all drill-down attributes of the cell
Example use:
for row in result.table_rows(dimension): print "%s: %s" % (row.label, row.record["record_count"])
dimension has to be cubes.Dimension object. Raises TypeError when cut for dimension is not PointCut.
- to_dict()¶
Return dictionary representation of the aggregation result. Can be used for JSON serialisation.
- class cubes.CalculatedResultIterator(calculators, iterator)¶
Iterator that decorates data items
Slicing and Dicing¶
- class cubes.Cell(cube=None, cuts=None)¶
Part of a cube determined by slicing dimensions. Immutable object.
- contains_level(dim, level, hierarchy=None)¶
Returns True if one of the cuts contains level of dimension dim. If hierarchy is not specified, then dimension’s default hierarchy is used.
- cut_for_dimension(dimension)¶
Return first found cut for given dimension
- deepest_levels(include_empty=False)¶
Returns a list of tuples: (dimension, hierarchy, level) where level is the deepest level specified in the respective cut. If no level is specified (empty path) and include_empty is True, then the level will be None. If include_empty is True then empty levels are not included in the result.
This method is currently used for preparing the periods-to-date conditions.
See also: cubes.Drilldown.deepest_levels()
- dimension_cuts(dimension, exclude=False)¶
Returns cuts for dimension. If exclude is True then the effect is reversed: return all cuts except those with dimension.
- drilldown(dimension, value, hierarchy=None)¶
Create another cell by drilling down dimension next level on current level’s key value.
Example:
cell = cubes.Cell(cube) cell = cell.drilldown("date", 2010) cell = cell.drilldown("date", 1)
is equivalent to:
cut = cubes.PointCut(“date”, [2010, 1]) cell = cubes.Cell(cube, [cut])Reverse operation is cubes.rollup("date")
Works only if the cut for dimension is PointCut. Otherwise the behaviour is undefined.
If hierarchy is not specified (by default) then default dimension hierarchy is used.
Returns new derived cell object.
- is_base(dimension, hierarchy=None)¶
Returns True when cell is base cell for dimension. Cell is base if there is a point cut with path referring to the most detailed level of the dimension hierarchy.
- level_depths()¶
Returns a dictionary of dimension names as keys and level depths (index of deepest level).
- multi_slice(cuts)¶
Create another cell by slicing through multiple slices. cuts is a list of Cut object instances. See also Cell.slice().
- point_cut_for_dimension(dimension)¶
Return first point cut for given dimension
- point_slice(dimension, path)¶
Create another cell by slicing receiving cell through dimension at path. Receiving object is not modified. If cut with dimension exists it is replaced with new one. If path is empty list or is none, then cut for given dimension is removed.
Example:
full_cube = Cell(cube) contracts_2010 = full_cube.point_slice("date", [2010])
Returns: new derived cell object.
Warning
Depreiated. Use cell.slice() instead with argument PointCut(dimension, path)
- public_cell()¶
Returns a cell that contains only non-hidden cuts. Hidden cuts are mostly generated cuts by a backend or an extension. Public cell is a cell to be presented to the front-end.
- rollup(rollup)¶
Rolls-up cell - goes one or more levels up through dimension hierarchy. It works in similar way as drill down in AggregationBrowser.aggregate() but in the opposite direction (it is like cd .. in a UNIX shell).
Roll-up can be:
- a string - single dimension to be rolled up one level
- an array - list of dimension names to be rolled-up one level
- a dictionary where keys are dimension names and values are levels to be rolled up-to
Note
Only default hierarchy is currently supported.
- rollup_dim(dimension, level=None, hierarchy=None)¶
Rolls-up cell - goes one or more levels up through dimension hierarchy. If there is no level to go up (we are at the top level), then the cut is removed.
If no hierarchy is specified, then the default dimension’s hierarchy is used.
Returns new cell object.
- slice(cut)¶
Returns new cell by slicing receiving cell with cut. Cut with same dimension as cut will be replaced, if there is no cut with the same dimension, then the cut will be appended.
- to_dict()¶
Returns a dictionary representation of the cell
- to_str()¶
Return string representation of the cell by using standard cuts-to-string conversion.
Cuts¶
- class cubes.Cut(dimension, hierarchy=None, invert=False, hidden=False)¶
Abstract class for a cell cut.
- level_depth()¶
Returns deepest level number. Subclasses should implement this method
- to_dict()¶
Returns dictionary representation fo the receiver. The keys are: dimension.
- class cubes.PointCut(dimension, path, hierarchy=None, invert=False, hidden=False)¶
Object describing way of slicing a cube (cell) through point in a dimension
- level_depth()¶
Returns index of deepest level.
- to_dict()¶
Returns dictionary representation of the receiver. The keys are: dimension, type`=``point` and path.
- class cubes.RangeCut(dimension, from_path, to_path, hierarchy=None, invert=False, hidden=False)¶
Object describing way of slicing a cube (cell) between two points of a dimension that has ordered points. For dimensions with unordered points behaviour is unknown.
- level_depth()¶
Returns index of deepest level which is equivalent to the longest path.
- to_dict()¶
Returns dictionary representation of the receiver. The keys are: dimension, type`=``range`, from and to paths.
- class cubes.SetCut(dimension, paths, hierarchy=None, invert=False, hidden=False)¶
Object describing way of slicing a cube (cell) between two points of a dimension that has ordered points. For dimensions with unordered points behaviour is unknown.
- level_depth()¶
Returns index of deepest level which is equivalent to the longest path.
- to_dict()¶
Returns dictionary representation of the receiver. The keys are: dimension, type`=``range` and set as a list of paths.
Drilldown¶
- class cubes.Drilldown(drilldown=None, cell=None)¶
Creates a drilldown object for drilldown specifictation of cell. The drilldown object can be used by browsers for convenient access to various drilldown properties.
Attributes:
- drilldown – list of drilldown items (named tuples) with attributes:
dimension, hierarchy, levels and keys
dimensions – list of dimensions used in this drilldown
The Drilldown object can be accessed by item index drilldown[0] or dimension name drilldown["date"]. Iterating the object yields all drilldown items.
- all_attributes()¶
Returns attributes of all levels in the drilldown. Order is by the drilldown item, then by the levels and finally by the attribute in the level.
- deepest_levels()¶
Returns a list of tuples: (dimension, hierarchy, level) where level is the deepest level drilled down to.
This method is currently used for preparing the periods-to-date conditions.
See also: cubes.Cell.deepest_levels()
- drilldown_for_dimension(dim)¶
Returns drilldown items for dimension dim.
- high_cardinality_levels(cell)¶
Returns list of levels in the drilldown that are of high cardinality and there is no cut for that level in the cell.
- items_as_strings()¶
Returns drilldown items as strings: dimension@hierarchy:level. If hierarchy is dimension’s default hierarchy, then it is not included in the string: dimension:level
- result_levels(include_split=False)¶
Returns a dictionary where keys are dimension names and values are list of level names for the drilldown. Use this method to populate the result levels attribute.
If include_split is True then split dimension is included.
- cubes.levels_from_drilldown(cell, drilldown, simplify=True)¶
Converts drilldown into a list of levels to be used to drill down. drilldown can be:
- list of dimensions
- list of dimension level specifier strings
- (dimension@hierarchy:level) list of tuples in form (dimension, hierarchy, levels, keys).
If drilldown is a list of dimensions or if the level is not specified, then next level in the cell is considered. The implicit next level is determined from a `PointCut for dimension in the cell.
For other types of cuts, such as range or set, “next” level is the first level of hierarachy.
If simplify is True then dimension references are simplified for flat dimensions without details. Otherwise full dimension attribute reference will be used as level_key.
Returns a list of drilldown items with attributes: dimension, hierarchy and levels where levels is a list of levels to be drilled down.
String conversions¶
In applications where slicing and dicing can be specified in form of a string, such as arguments of HTTP requests of an web application, there are couple helper methods that do the string-to-object conversion:
- cubes.cuts_from_string(cube, string, member_converters=None, role_member_converters=None)¶
Return list of cuts specified in string. You can use this function to parse cuts encoded in a URL.
Arguments:
- string – string containing the cut descritption (see below)
- cube – cube for which the cuts are being created
- member_converters – callables converting single-item values into paths. Keys are dimension names.
- role_member_converters – callables converting single-item values into paths. Keys are dimension role names (Dimension.role).
Examples:
date:2004 date:2004,1 date:2004,1|class=5 date:2004,1,1|category:5,10,12|class:5
Ranges are in form from-to with possibility of open range:
date:2004-2010 date:2004,5-2010,3 date:2004,5-2010 date:2004,5- date:-2010
Sets are in form path1;path2;path3 (none of the paths should be empty):
date:2004;2010 date:2004;2005,1;2010,10
Grammar:
<list> ::= <cut> | <cut> '|' <list> <cut> ::= <dimension> ':' <path> <dimension> ::= <identifier> <path> ::= <value> | <value> ',' <path>
The characters ‘|’, ‘:’ and ‘,’ are configured in CUT_STRING_SEPARATOR, DIMENSION_STRING_SEPARATOR, PATH_STRING_SEPARATOR respectively.
- cubes.string_from_cuts(cuts)¶
Returns a string represeting cuts. String can be used in URLs
- cubes.string_from_path(path)¶
Returns a string representing dimension path. If path is None or empty, then returns empty string. The ptah elements are comma , spearated.
Raises ValueError when path elements contain characters that are not allowed in path element (alphanumeric and underscore _).
- cubes.path_from_string(string)¶
Returns a dimension point path from string. The path elements are separated by comma , character.
Returns an empty list when string is empty or None.
- cubes.string_to_drilldown(astring)¶
Converts astring into a drilldown tuple (dimension, hierarchy, level). The string should have a format: dimension@hierarchy:level. Hierarchy and level are optional.
Raises ArgumentError when astring does not match expected pattern.
Mapper¶
- class cubes.Mapper(cube, locale=None, schema=None, fact_name=None, **options)¶
Abstract class for mappers which maps logical references to physical references (tables and columns).
Attributes:
- cube - mapped cube
- simplify_dimension_references – references for flat dimensions (with one level and no details) will be just dimension names, no attribute name. Might be useful when using single-table schema, for example, with couple of one-column dimensions.
- fact_name – fact name, if not specified then cube.name is used
- schema – default database schema
- all_attributes(expand_locales=False)¶
Return a list of all attributes of a cube. If expand_locales is True, then localized logical reference is returned for each attribute’s locale.
- attribute(name)¶
Returns an attribute with logical reference name.
- logical(attribute, locale=None)¶
Returns logical reference as string for attribute in dimension. If dimension is Null then fact table is assumed. The logical reference might have following forms:
- dimension.attribute - dimension attribute
- attribute - fact measure or detail
If simplify_dimension_references is True then references for flat dimensios without details is dimension.
If locale is specified, then locale is added to the reference. This is used by backends and other mappers, it has no real use in end-user browsing.
- physical(attribute, locale=None)¶
Returns physical reference for attribute. Returned value is backend specific. Default implementation returns a value from the mapping dictionary.
This method should be implemented by Mapper subclasses.
- set_locale(locale)¶
Change the mapper’s locale
- split_logical(reference)¶
Returns tuple (dimension, attribute) from logical_reference string. Syntax of the string is: dimensions.attribute.